· engineering · 10 min read
By Akshar PatelLLMs Make Bad API Contracts More Expensive
A vague API spec used to waste human time. Now it wastes generators, mocks, validators, drift tooling, and agents all at once. AI does not cancel out sloppy contracts. It amplifies them.
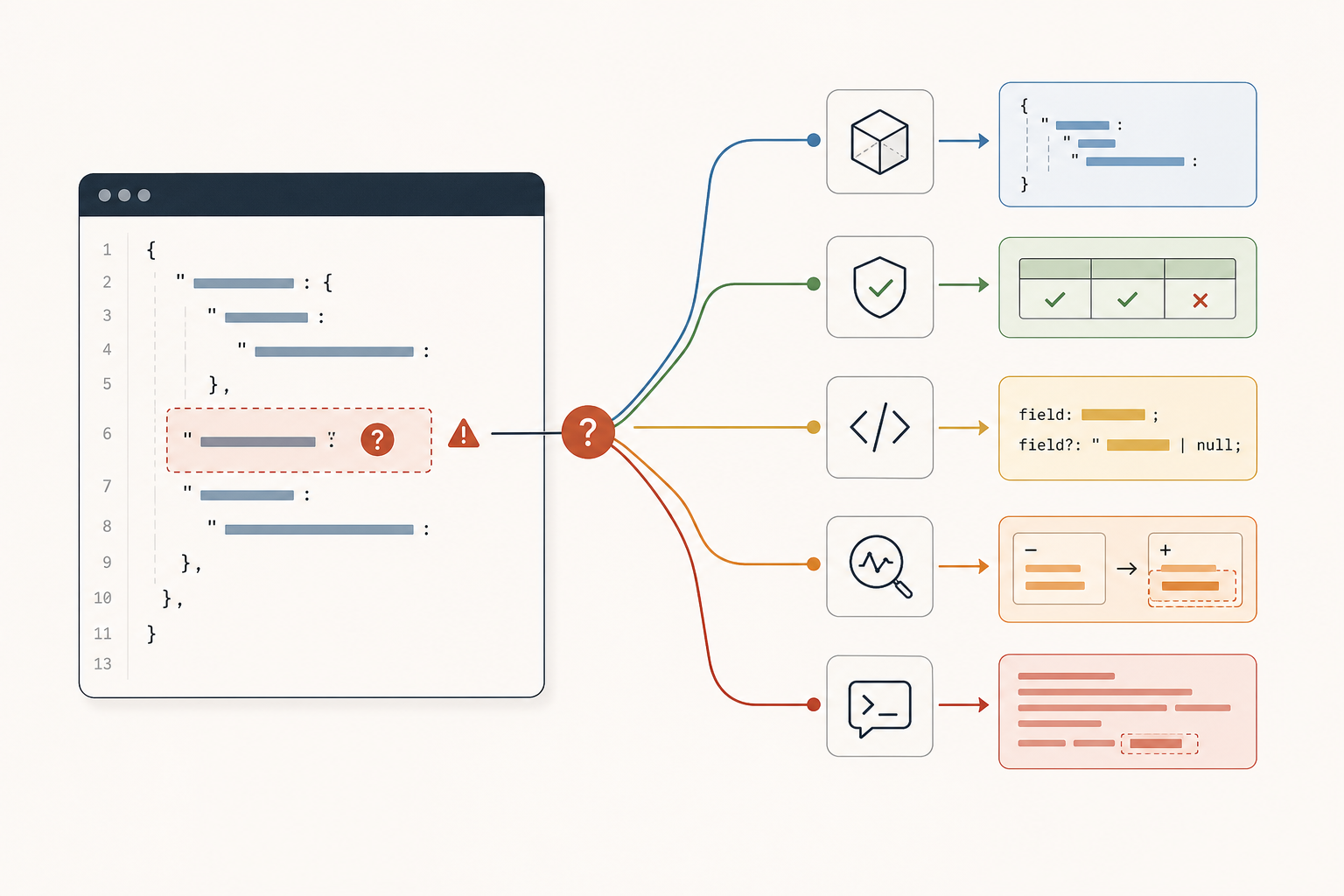
LLMs do not make weak API contracts less important. They make them more expensive.
Before AI, a vague spec mostly confused humans. A developer had to guess what status really meant, whether id was a UUID or an integer, or whether /users and /v1/users were both supposed to work. That was annoying, but the damage was bounded by how many people touched the API.
Now the same sloppiness spreads through code generation, mock data, validators, drift detection, request-history-derived specs, and agent workflows. One unclear enum or one hand-wavy example no longer creates one misunderstanding. It creates five or six, all in slightly different ways, and they feed each other.
That changes the economics of API quality. AI does not paper over a bad contract. It turns hidden contract debt into an active systems problem.
A vague contract used to fail slowly
Old API ambiguity was familiar.
- The backend team knew the real response shape, but the spec lagged.
- The frontend team copied a working payload from a log or a Slack thread.
- QA used a mock that was close enough.
- Somebody eventually discovered that
customerIdwas sometimes a string and sometimes a number.
The damage was real, but it was often local. Humans are surprisingly good at patching over missing detail. They ask each other. They recognize inconsistent naming. They notice when an example looks suspicious.
Machines do not do that kind of repair cleanly.
They literalize whatever contract you gave them.
AI multiplies every unclear field
This became obvious while working on spec-driven mocking and OpenAPI tooling.
If a schema says status: string, an LLM or Faker-backed generator has to invent what kind of string that is. Is it pending or PENDING? Is it one of five business states, or literally any text? If the contract does not say, the system has to guess.
That is exactly where descriptions and realistic examples start paying for themselves. A short field description can explain whether status is a user-facing lifecycle state, an internal workflow marker, or a billing state. A good example can show the intended casing and the kind of values the system should expect. Those small additions narrow the space of plausible guesses before any model or tool starts filling in the blanks.
That guess leaks everywhere:
- The mock server generates values that look plausible but are operationally wrong.
- The validator accepts shapes that should have been rejected.
- The example response in the docs becomes broader than the real API.
- A generated client bakes in the wrong assumption.
- An agent writing integration code treats the guessed shape as ground truth.
Humans used to absorb that ambiguity one conversation at a time. AI pipelines industrialize it.
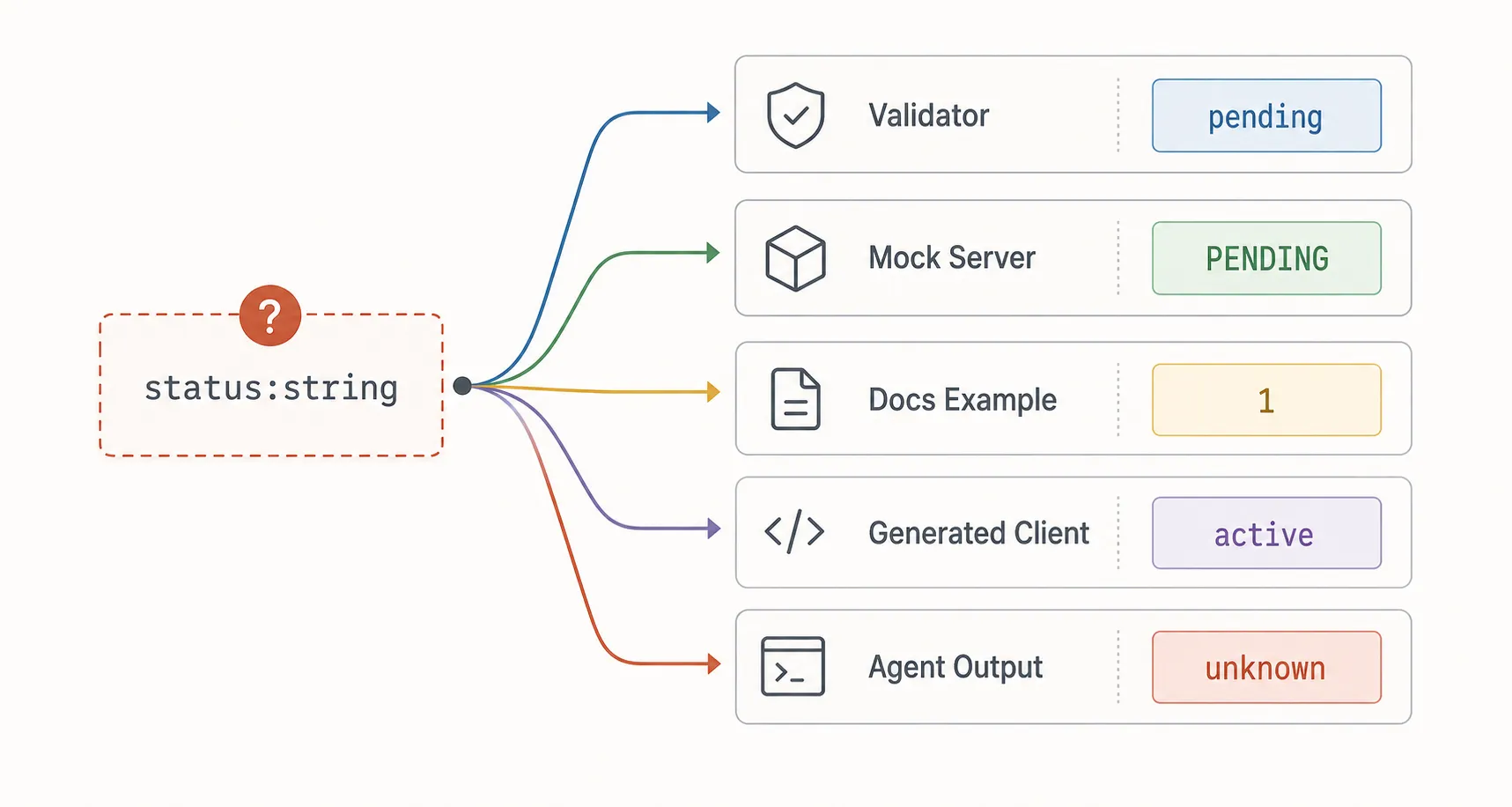
”Smart” mocking is only as smart as the contract
Schema-aware mocking sounds like the place where AI should save you. In practice, it mostly exposes how underspecified many APIs are.
If a field is called email, good tools can infer a lot. If a field is called createdAt, they can usually generate something sensible. Enums, formats, examples, and descriptions make the output dramatically better.
But real contracts are full of fields like these:
{
"type": "string",
"name": "code"
}What is code?
- A six-digit OTP?
- An airport code?
- An internal error identifier?
- A coupon?
- A country code?
The fix is not “use more AI.” The fix is to make the field more concrete. If code really means one of a known set of business states, make it an enum. If it has a fixed format, encode that. If it represents a specific domain concept, describe that concept directly instead of leaving the tool to reverse-engineer it from the name alone.
You can add Faker integration, prompt tuning, enum heuristics, ID heuristics, retry logic, manual mappings, editable mappings, separate storage for faker mappings, parsed request-body caching, and spec regeneration flows. We did exactly that because it materially improves output.
But all of those improvements are compensation mechanisms. They are ways of narrowing ambiguity after the contract has already failed to say enough.
The stronger the generation system gets, the more clearly you see where the spec stopped carrying its weight.
Bad examples poison good validators
There is a common assumption that a formal schema will save the day even if the prose is weak.
That is only half true.
Validators are strict only about what the schema actually encodes. If the schema is broad, the validator will faithfully approve broad nonsense. If additionalProperties is loose, if nullable behavior is inconsistent, if a response is described as object with no real shape, then the validator is not protecting the contract. It is laundering vagueness into false confidence.
Examples make this worse when they contradict the schema or quietly introduce extra conventions.
A weak example teaches both humans and machines the wrong lesson:
- the docs reader copies it
- the LLM uses it as pattern evidence
- the mock generator tries to imitate it
- the test fixture freezes it into CI
Now you have a contract that is technically valid, practically misleading, and machine-replicated.
Naming inconsistency is no longer a cosmetic issue
People often dismiss naming problems as style issues. They are not.
If one part of an API says userId, another says user_id, another says uid, and a fourth says id, an experienced engineer can often recover the intent from context. A generator or agent usually cannot. It sees four separate signals and has to decide whether they are aliases, different scopes, or entirely different fields.
The same goes for path design.
If your base URL handling is fuzzy, if full URLs and relative paths blur together, or if versioning is implied in some places and explicit in others, humans may muddle through. Tooling will not. You end up building UX just to make the contract legible again: clear paths, clear base URLs, clear full request URLs, obvious separation between what is structural and what is instance-level.
That kind of cleanup used to feel like documentation polish. In an AI-heavy workflow, it becomes execution infrastructure.
Drift tools expose contract debt in bulk
Drift detection is where vague contracts stop being an abstract quality complaint and start becoming a product problem.
When you compare observed traffic against an OpenAPI spec, every unclear rule creates noisy diffs:
- Was this actually a new enum value, or was the enum incomplete from day one?
- Is this a real response-shape change, or did the original spec flatten two variants into one?
- Did the API add a field, or did the generator miss it because the earlier response example was partial?
- Is this a new response, or the same response with one unstable nested field?
Once you start generating patches, previewing fixes, and applying them back into a spec, contract quality matters even more. The patch system has to decide what counts as a real change. That is much easier when descriptions are explicit, enums are complete, IDs are consistently typed, and response unions are intentional instead of accidental.
One of the more useful additions in this area is handling “new response” as its own drift type. That sounds obvious until you deal with real traffic. APIs rarely change in neat textbook ways. They accrete optional fields, alternate bodies, and edge-case payloads. If the original contract was already hand-wavy, your drift tooling spends its time arguing with history instead of surfacing meaningful change.
Building specs from traffic does not rescue a sloppy API
Another tempting belief is that if the hand-written spec is weak, AI can reconstruct a better one from request history.
That helps, but only up to a point.
Traffic-derived spec generation is useful for recovering paths, common shapes, example payloads, and missing endpoints. Description generation can make the output far more readable. Enum heuristics, response-body union merging, and noise filtering all improve the result.
But request history is not intent. It is evidence.
That distinction matters.
Traffic can show that a field has only ever been active or disabled. It cannot prove those are the only valid business states. It can show that discount was absent in 98 percent of requests. It cannot tell you whether that field is deprecated, premium-only, or just rare. It can infer that response bodies seem to split into two shapes. It cannot tell you whether those are stable variants or accidental drift from two teams shipping independently.
LLMs make this reconstruction feel more complete than it is. The output reads well, which can hide epistemic gaps.
A polished generated spec can still be wrong in the exact places where the original contract was weak.

Agents are obedient to the wrong details
This is the part many teams underestimate.
Agents are not just reading docs. They are taking actions based on them.
If an agent has access to your OpenAPI file, mock server, validation rules, and recent traffic summaries, it will synthesize all of them into an operational model of the API. That sounds powerful. It is also a very efficient way to spread contract mistakes across implementation, testing, and support workflows.
Agents are especially vulnerable to:
- vague descriptions that sound confident but say nothing testable
- weak or missing enums
- inconsistent field names across endpoints
- examples that encode unofficial conventions
- response schemas that collapse distinct cases into one blob
A human engineer often pauses when something feels off. An agent usually proceeds with the most statistically supported interpretation available in context.
If the context is sloppy, the agent becomes a high-speed ambiguity amplifier.
This is why contract UX matters now
A lot of API work that looked secondary a few years ago now matters much more:
- making paths readable instead of barely parseable
- separating base URLs from request URLs cleanly
- preserving practical examples, not toy ones
- storing manual mapping decisions instead of regenerating over them
- validating V1 to V2 migrations against real shapes instead of idealized ones
- keeping gRPC descriptors, protosets, reflection output, and productized contract views aligned
None of this is glamorous. It is the work that keeps machine consumers from hallucinating structure that was never actually specified.
The pattern is consistent across REST and gRPC. Once contracts become machine inputs instead of human reference documents, sloppiness stops being passive. It starts causing active downstream behavior.
What teams should do instead
If your team is investing in AI-assisted API development, the boring fixes move up the priority list.
Write down the enum. Stabilize the naming. Add descriptions that disambiguate business meaning, not just datatype. Keep examples realistic and schema-matching. Be explicit about nullable fields, unions, IDs, and version boundaries. Treat drift noise as a contract smell, not just a tooling annoyance.
Keep a human in the loop as well. The machine can infer patterns from schemas, traffic, and examples, but it does not actually know the business rule that only appears during a refund, a partial shipment, a failed compliance check, or the one customer tier with legacy behavior. Humans bring the domain knowledge and edge-case awareness that keeps a plausible contract from becoming a wrong one.
Most of all, stop assuming a good prompt can compensate for a bad definition.
It can compensate for some of it. That is the trap.
The first generation of AI tooling often looks impressive because it can guess around missing detail. The second generation forces you to operationalize those guesses across mocks, validators, generated SDKs, replay systems, migration tooling, and agents. That is when the hidden cost shows up.
AI raises the price of ambiguity
The old story was that vague API contracts slowed teams down.
The new story is harsher: vague API contracts now create machine-scale confusion.
Every missing enum, unstable field name, weak example, or underspecified response shape is no longer just a documentation flaw. It is training data for the wrong behavior in every system downstream of the contract.
That is why LLMs make bad API contracts more expensive, not less.
They do not remove the need for precision. They raise the penalty for pretending precision was optional.